![]() USU
››
व्यापार स्वचालन के लिए कार्यक्रम
››
क्लिनिक के लिए कार्यक्रम
››
चिकित्सा कार्यक्रम के लिए निर्देश
››
USU
››
व्यापार स्वचालन के लिए कार्यक्रम
››
क्लिनिक के लिए कार्यक्रम
››
चिकित्सा कार्यक्रम के लिए निर्देश
››
![]() ये सुविधाएँ केवल मानक और व्यावसायिक प्रोग्राम कॉन्फ़िगरेशन में उपलब्ध हैं।
ये सुविधाएँ केवल मानक और व्यावसायिक प्रोग्राम कॉन्फ़िगरेशन में उपलब्ध हैं।

जब हमने लगाना सीखा ![]() प्रकाश फिल्टर , जहां हम बस किसी भी क्षेत्र के वांछित मूल्यों पर निशान लगाते हैं। यह कठिन परिस्थितियों को काम करने का समय है, ताकि एक मॉड्यूल के उदाहरण का उपयोग किया जा सके "मरीजों" देखें कि एक जटिल डेटा फ़िल्टरिंग सेटअप कैसे काम करता है।
प्रकाश फिल्टर , जहां हम बस किसी भी क्षेत्र के वांछित मूल्यों पर निशान लगाते हैं। यह कठिन परिस्थितियों को काम करने का समय है, ताकि एक मॉड्यूल के उदाहरण का उपयोग किया जा सके "मरीजों" देखें कि एक जटिल डेटा फ़िल्टरिंग सेटअप कैसे काम करता है।
साथ ![]() पिछले उदाहरण में, फ़िल्टर विंडो में हमारे पास पहले से ही एक शर्त है।
पिछले उदाहरण में, फ़िल्टर विंडो में हमारे पास पहले से ही एक शर्त है।
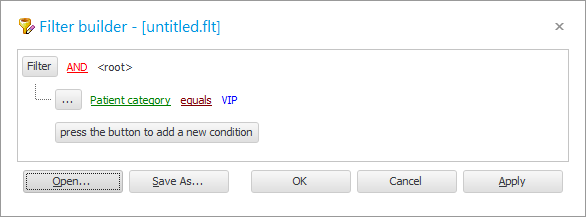
आइए ' रोगी श्रेणी ' फ़ील्ड को ' नाम ' फ़ील्ड से बदलें।
तुलना चिह्न को ' बराबर ' से ' समान ' में बदलें।
मान के रूप में, ' %van% ' दर्ज करें।
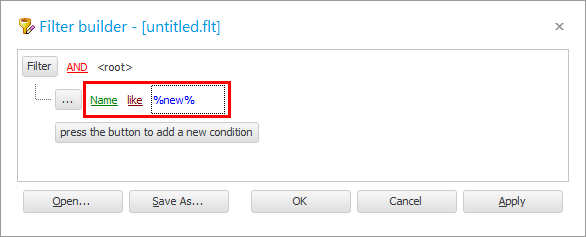
' ओके ' बटन दबाएं और परिणाम देखें।
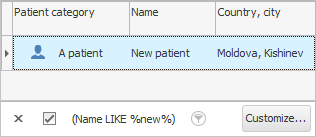
हमने क्या किया है? हमने उन प्रविष्टियों को देखना सीख लिया है जो हमारे द्वारा लिखी गई बातों से मेल खाती हैं । इसलिए हमें तुलना चिह्न ' जैसा दिखता है ' की आवश्यकता है। और शब्द ' %van% ' के बाएँ और दाएँ प्रतिशत चिह्न का अर्थ है कि उन्हें फ़ील्ड में 'किसी भी पाठ' से बदला जा सकता है "रोगी का नाम" .
इस मामले में, हमें उन सभी कर्मचारियों को दिखाया गया जिनके पहले या अंतिम नाम या गोत्र में 'इवान' शब्द है। यह 'इवांस', और 'इवानोव्स', और 'इवानिकोव्स', और 'इवानोविची' आदि हो सकते हैं। यह तंत्र उपयोग करने के लिए सुविधाजनक है जब आप नहीं जानते कि रोगी का ' पूरा नाम ' डेटाबेस में कैसे लिखा जाता है। और जब सभी समान रिकॉर्ड प्रदर्शित होते हैं, तो आप अपनी आँखों से आसानी से सही व्यक्ति का चयन कर सकते हैं।
प्रतिशत चिह्न का उपयोग न केवल खोज वाक्यांश के आरंभ और अंत में किया जा सकता है, बल्कि बीच में भी किया जा सकता है। फिर आप पहले नाम का हिस्सा और अंतिम नाम का हिस्सा निर्दिष्ट कर सकते हैं। उदाहरण के लिए, ' न्यू क्लाइंट ' के बजाय ' %ov%lie% ' लिखना संभव है। लंबे नाम के मामले में, ऐसा लुकअप मैकेनिज्म टाइपिंग के समय को बहुत कम कर देता है।

अंत में, जब आपने डेटा फ़िल्टरिंग के साथ प्रयोग करना समाप्त कर लिया है, तो फ़िल्टरिंग पैनल के बाईं ओर 'क्रॉस' पर क्लिक करके फ़िल्टर को रद्द कर दें।

![]() आइए अब कई शर्तों के साथ फ़िल्टरिंग देखें
आइए अब कई शर्तों के साथ फ़िल्टरिंग देखें ![]() समूहीकृत किया जा सकता है ।
समूहीकृत किया जा सकता है ।
अन्य उपयोगी विषयों के लिए नीचे देखें:
![]()
यूनिवर्सल अकाउंटिंग सिस्टम
2010 - 2024
 इंटरैक्टिव प्रशिक्षण के साथ कार्यक्रम डाउनलोड करें
इंटरैक्टिव प्रशिक्षण के साथ कार्यक्रम डाउनलोड करें